Unlock the Power of Unstructured Data with Tensorlake: Scalable Document Ingestion and Serverless Workflows
Tensorlake comes in — a powerful AI Data Cloud platform designed to streamline document ingestion and data orchestration with unmatched scalability and precision.
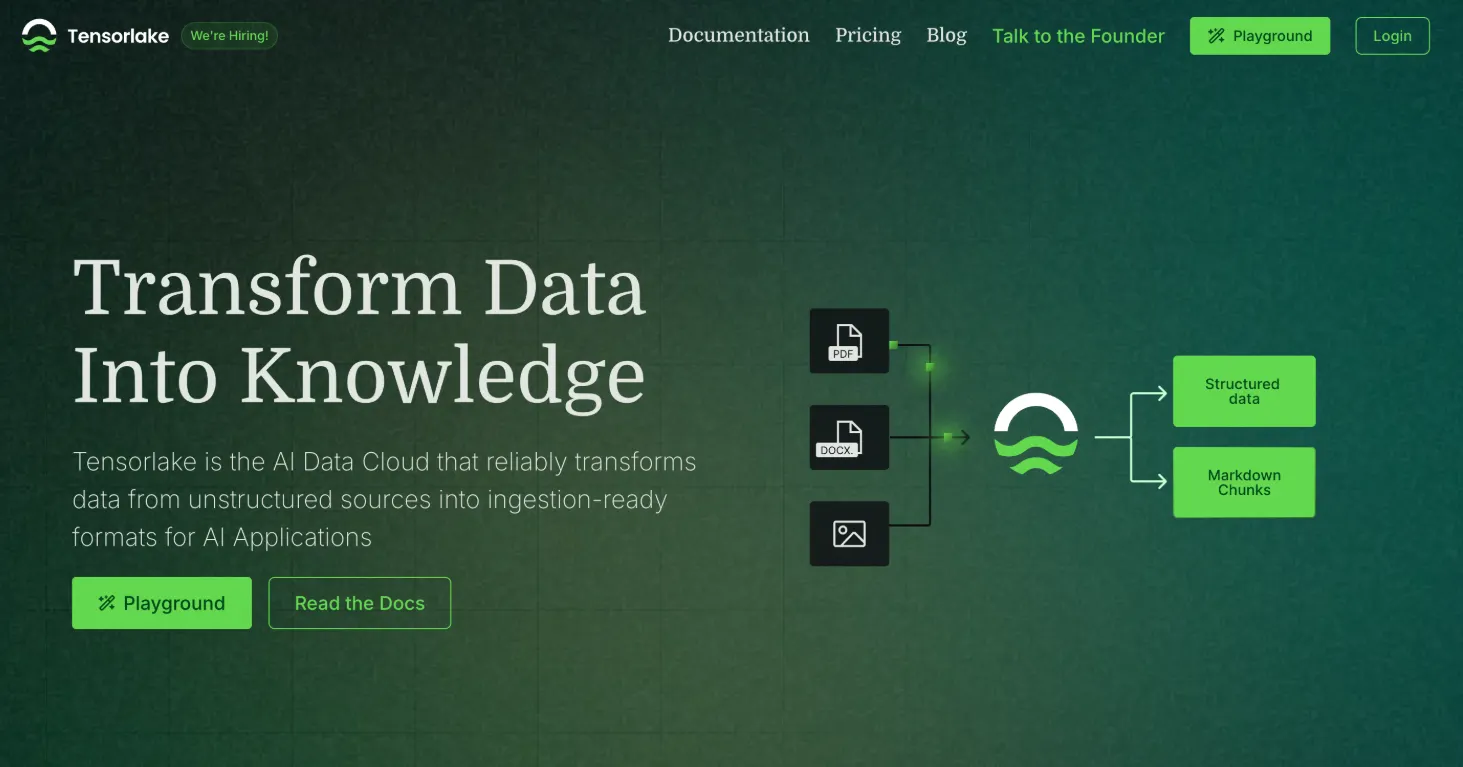
In today’s data-driven world, transforming unstructured documents into actionable, AI-ready data is a game-changer for businesses. Whether you’re dealing with PDFs, spreadsheets, handwritten notes, or presentations, extracting high-quality insights efficiently is critical. That’s where Tensorlake comes in — a powerful AI Data Cloud platform designed to streamline document ingestion and data orchestration with unmatched scalability and precision.
Why Tensorlake?
Tensorlake simplifies the complexity of document parsing and data processing with two core capabilities: Document Ingestion APIs and Serverless Workflows. Built on fully managed infrastructure with GPU acceleration, Tensorlake empowers developers to focus on innovation while the platform handles the heavy lifting of parsing, extracting, and orchestrating workflows. Here’s how it works:
1. Document Ingestion: Turn Any File into AI-Ready Data
Tensorlake’s Document Ingestion APIs make it easy to convert unstructured documents into structured formats like markdown or JSON, optimized for Retrieval-Augmented Generation (RAG) systems, knowledge bases, or analytics. Key features include:
- Parse Any File Type: From PDFs and DOCX to images and complex spreadsheets, Tensorlake supports a wide range of formats with human-like layout understanding.
- Advanced Parsing Options: Customize chunking strategies (e.g., by section or page), enable table extraction, signature detection, and even figure summarization for deeper insights.
- Structured Extraction: Extract specific data fields using JSON schemas or Pydantic models. For example, pull invoice numbers, totals, and due dates from financial documents with ease.
- Scalable Datasets: Organize documents into auto-parsed datasets for batch processing, with webhook support for real-time updates.
Here’s a quick example of parsing a document with Tensorlake’s SDK:
from tensorlake.documentai import DocumentAI, ParseStatus
doc_ai = DocumentAI(api_key="your-api-key")
file_id = doc_ai.upload("/path/to/document.pdf")
parse_id = doc_ai.parse(file_id)
result = doc_ai.wait_for_completion(parse_id)
if result.status == ParseStatus.SUCCESSFUL:
for chunk in result.chunks:
print(chunk.content) # Clean markdown output
For advanced customization, you can fine-tune parsing options like chunking strategies or table output formats, ensuring the output meets your specific needs.
2. Serverless Workflows: Build Scalable Data Pipelines
Tensorlake’s serverless workflows let you create and deploy Python-based Workflow APIs that scale effortlessly from a handful of documents to millions. These workflows run on fully managed cloud infrastructure, scaling up or down based on demand — without the need for external databases or map-reduce engines.
Here’s an example of a workflow that processes a sequence of numbers, computes their squares, sums them, and sends the result to a web service:
from tensorlake import Graph, tensorlake_function
@tensorlake_function()
def generate_sequence(last_sequence_number: int) -> List[int]:
return [i for i in range(last_sequence_number + 1)]
@tensorlake_function()
def squared(number: int) -> int:
return number * number
@tensorlake_function(accumulate=int)
def sum_all(current_sum: int, number: int) -> int:
return current_sum + number
@tensorlake_function()
def send_to_web_service(value: int) -> str:
url = f"https://example.com/?number={value}"
with urllib.request.urlopen(url) as response:
return response.read()
g = Graph(name="example_workflow", start_node=generate_sequence)
g.add_edge(generate_sequence, squared)
g.add_edge(squared, sum_all)
g.add_edge(sum_all, send_to_web_service)
g.run(last_sequence_number=200, block_until_done=True)
Deploy this workflow to Tensorlake Cloud with a single command:
tensorlake deploy examples/readme_example.py
Why Choose Tensorlake?
- High Accuracy: Layout-aware parsing mimics human understanding, preserving tables, metadata, and visual elements like signatures.
- Scalability: Process thousands to millions of documents with low latency and cost-efficient serverless workflows.
- Developer-Friendly: Build workflows in Python, integrate with existing systems, and deploy on managed GPU infrastructure.
- Secure by Design: Role-Based Access Control (RBAC) and namespaces ensure data protection and compliance.
Real-World Impact
Tensorlake is already transforming how organizations handle complex documents. As Ryland Goldstein, Head of Product at Temporal.io, said: “Being able to easily process millions of documents at once, while maintaining context and relationships between emails, PDFs, sheets, everything! It’s not just about the speed, it’s the intelligent data extraction that makes this a game changer.”
Get Started Today
Ready to unlock the potential of your unstructured data? Install the Tensorlake SDK with pip install tensorlake, sign up for an API key at cloud.tensorlake.ai, and explore the documentation for detailed guides on document parsing, structured extraction, and serverless workflows.
#AI #DataProcessing #DocumentIngestion #Serverless #Python #Tensorlake

Talk to our Career Advisor
Speak with our career advisor to get clear direction, understand the right opportunities, and take the next step in your career with confidence.

Get Your Course Brochure Now
Fill in your details and receive complete course information instantly.
- Detailed course syllabus & modules
- Duration, fees & learning format
- Certification & career opportunities
- Placement support & real-world projects
- Demo class & expert guidance info
Copyright © 2026, Edvora. All Rights Reserved.
